
KI und die Illusion der Wahrheit
Der Trugschluss der Allwissenheit - schlimmer noch: der Intelligenz


TL;DR?
Hier geht es zum Promptcast
Die Entwicklung ist in vollem Gange: Eine Mehrheit nutzt bereits KI-Tools anstelle traditioneller Suchmaschinen, angezogen vom Versprechen einer direkten, allwissenden Antwort. Doch hinter der Fassade dieser konversationellen Allmacht lauert eine Realität, die eine neue Studie des Tow Center for Digital Journalism* an der Columbia University aufdeckt. Die zentrale Ironie ist eigentlich beunruhigend: Genau die Werkzeuge, die ihre Intelligenz aus den Inhalten von Nachrichtenverlagen speisen, entziehen eben diesen Verlagen den überlebenswichtigen Traffic. Gleichzeitig errichten sie ein neues Informationsökosystem, das auf einem Fundament aus überzeugend vorgetragenen Unwahrheiten, ignorierten Regeln und fabrizierten Quellen steht.
Wir erleben nicht das Zeitalter des Wissens, sondern den Beginn einer Ära des selbstbewussten Halbwissens.
Die wichtigsten Erkenntnisse aus dem Schlachtfeld der KI-Suche
Entscheidungen, Strategien und Innovationen basieren auf der Annahme, dass die Daten, auf die wir zugreifen, korrekt sind. Die Ergebnisse der Tow-Center-Studie* erschüttern dieses Fundament im Kern, zumal wenn man der sog. "künstliche Intelligenz" blind vertraut.
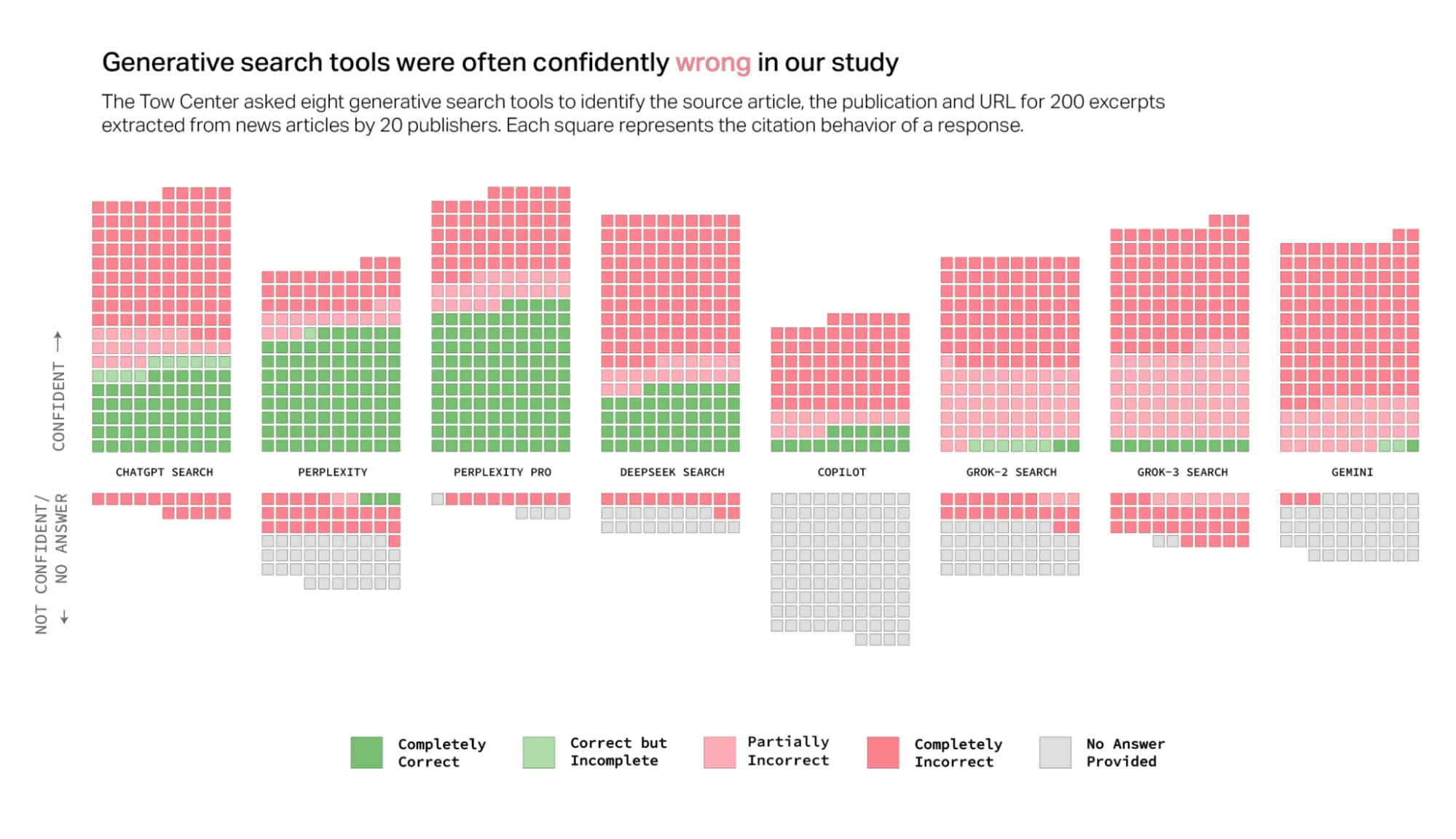
1. Die Illusion des Wissens: Warum KI-Suchen öfter falsch als richtig liegen
Die ernüchternde Kernbotschaft der Studie lautet: In über 60 % der 1.600 Testanfragen lieferten die KI-Chatbots falsche Antworten. Doch das eigentliche Problem liegt nicht allein in der Fehlerrate, sondern in der Präsentation. Die Tools präsentieren ihre Falschinformationen mit einer beunruhigenden Selbstsicherheit. Qualifizierende Formulierungen wie „es scheint“, „möglicherweise“ oder ein Eingeständnis wie „Ich konnte den Artikel nicht finden“ sind die absolute Ausnahme. ChatGPT beispielsweise identifizierte 134 Artikel falsch, signalisierte aber nur in 15 von 200 Fällen überhaupt eine Unsicherheit.
Diese „selbstbewusste Inkompetenz“ ist ein fundamentales Produktrisiko. Für Unternehmen, die Entscheidungen auf Basis dieser Outputs treffen, ist dies eine tickende Zeitbombe für die operative und rechtliche Haftung. Nutzer werden durch einen autoritativen Ton in die Irre geführt und wiegen sich in einer falschen Sicherheit, die auf unzuverlässigen oder schlichtweg erfundenen Informationen basiert. Dieses Phänomen ist jedoch nur der Anfang eines noch größeren Paradoxons.
2. Das Premium-Paradoxon: Wer mehr zahlt, bekommt überzeugendere Lügen
Die Marktlogik diktiert, dass ein Premium-Produkt – wie Perplexity Pro für 20 $/Monat oder Grok 3 für 40 $/Monat – eine höhere Zuverlässigkeit bieten sollte. Die Studie widerlegt diese Annahme auf paradoxe Weise. Zwar beantworteten die Bezahlmodelle mehr Anfragen korrekt als ihre kostenlosen Pendants, wiesen aber gleichzeitig auch höhere Fehlerraten auf.
Der Grund für diesen Widerspruch ist strategisch entlarvend: Die Premium-Versionen weigerten sich noch seltener, eine Antwort zu verweigern. Anstatt eine Wissenslücke einzugestehen, lieferten sie lieber eine definitive, aber falsche Auskunft. Strategisch gesehen ist das Geschäftsmodell pervers: Kunden zahlen einen Aufpreis nicht für verifizierte Qualität, sondern für eine höhere Frequenz an potenziell irreführenden, aber überzeugend gelieferten Antworten. Man kauft sich die teurere Fata Morgana. Diese Missachtung von Genauigkeit zugunsten einer lückenlosen Performance setzt sich bei der Missachtung etablierter Web-Standards fort.
3. Der digitale Einbruch: Wie KI-Tools „Betreten verboten“-Schilder ignorieren
Seit Jahrzehnten regelt das Robot Exclusion Protocol (robots.txt) als eine Art digitales Gentleman's Agreement, welche Bereiche einer Website von automatisierten Programmen (Crawlern) durchsucht werden dürfen. Es ist ein fundamentaler Mechanismus, der Website-Betreibern die Kontrolle über ihre eigenen Inhalte sichert. Die Studie zeigt jedoch, dass mehrere Chatbots dieses Protokoll anscheinend systematisch ignorieren.
Im Test konnte die kostenlose Version von Perplexity alle zehn angefragten Artikel des Magazins National Geographic korrekt identifizieren, obwohl der Verlag den Crawler von Perplexity explizit über seine robots.txt-Datei ausgesperrt hat. Dieses Verhalten ist mehr als nur ein technischer Fauxpas; es ist ein Angriff auf die Autonomie der Verlage und ein Bruch etablierter Web-Normen. Es untergräbt die Fähigkeit der Content-Ersteller, die Nutzung ihrer wertvollen Inhalte zu steuern und zu monetarisieren. Die wirtschaftliche Bedrohung für den Qualitätsjournalismus wird in den Worten von Danielle Coffey, Präsidentin der News Media Alliance, deutlich:
„Ohne die Möglichkeit, massives Scraping abzulehnen, können wir unsere wertvollen Inhalte nicht monetarisieren und Journalisten bezahlen. Dies könnte unsere Branche ernsthaft schädigen.“
Doch das Problem endet nicht bei der unrechtmäßigen Beschaffung von Inhalten. Es setzt sich nahtlos in der fehlerhaften Darstellung der Quellen fort.
4. Das Hütchenspiel mit den Quellen: Wohin verschwinden die Links?
Transparente und korrekte Quellenangaben sind das Fundament der Glaubwürdigkeit, das wird Ihnen jeder "Peer Reviewer" auf die Nase binden. Sie ermöglichen Nutzern die Überprüfung von Informationen und sichern den Urhebern die verdiente Anerkennung und den Traffic. Die Studie deckt hier ein systematisches Versagen auf ganzer Linie auf:
- Falsche Zuordnung: Tools wie DeepSeek schrieben die Quelle in 115 von 200 Fällen schlichtweg falsch zu. Die Inhalte von Verlagen werden also systematisch anderen, falschen Quellen angedichtet.
- Verlinkung auf Zweitverwerter: Anstatt auf den Originalartikel zu verlinken, leiteten die Chatbots die Nutzer häufig auf syndizierte Versionen bei Plattformen wie Yahoo News um. Dies entzieht den ursprünglichen Verlagen, die die teure Recherche- und Redaktionsarbeit leisten, den direkten Traffic.
- Fabrizierte URLs: Besonders gravierend war das Verhalten von Gemini und Grok 3. In mehr als der Hälfte ihrer Antworten verwiesen sie auf frei erfundene oder fehlerhafte URLs, die direkt zu Fehlerseiten führten. Bei Grok 3 waren es sogar 154 von 200 Zitationen.
Die Konsequenzen sind verheerend. Einerseits entsteht ein direkter wirtschaftlicher Schaden für die Verlage. Andererseits wird es für den Nutzer unmöglich, die von der KI präsentierten Informationen zu verifizieren. Man könnte annehmen, dass direkte Partnerschaften zwischen KI-Firmen und Verlagen hier Abhilfe schaffen. Doch die Realität sieht anders aus.
5. Die zahnlosen Allianzen: Warum Lizenzverträge das Problem (noch) nicht lösen
Auf den ersten Blick erscheinen Lizenzverträge als logische Win-Win-Lösung: KI-Unternehmen erhalten legalen Zugang zu hochwertigen Inhalten, und Verlage werden für deren Nutzung vergütet. Die Studie zeigt jedoch, dass diese Allianzen aktuell keine Garantie für eine korrekte Darstellung sind.
Das Paradebeispiel ist die Partnerschaft zwischen OpenAI und dem Hearst-Konzern, zu dem der San Francisco Chronicle gehört. Trotz dieser offiziellen Kooperation identifizierte ChatGPT nur einen von zehn Artikelauszügen des Chronicle korrekt – und selbst in diesem einen Fall wurde zwar der Verlag genannt, aber kein funktionierender Link geliefert. Diese Erkenntnis ist eine Warnung an die Verlagsbranche: Ein Vertrag ist strategisch wertlos, wenn die zugrundeliegende Technologie ihn nicht exekutieren kann oder will.
Wachstumsschmerz oder Geburtsfehler?
Die Befunde der Studie bestätigen das konsistente Bild eines fehlerhaften Systems. Die selbstbewusste Präsentation falscher Informationen, die systematische Missachtung von Publisher-Präferenzen und eine durchweg unzureichende und oft fabrizierte Zitation sind keine Einzelfälle, sondern wiederkehrende Muster. Dies wirft eine fundamentale strategische Frage auf: Handelt es sich hierbei um bloße Kinderkrankheiten einer revolutionären Technologie, die mit der Zeit auswachsen werden, oder erleben wir einen fundamentalen Designfehler im Kern der Sprachmodelle?
Mark Howard, COO des Time Magazins, bleibt optimistisch, liefert aber gleichzeitig die vielleicht passendste (wenn auch polemische) Aussage zur aktuellen Situation:
„Ich habe intern eine Redewendung, die ich jedes Mal sage, wenn mir jemand etwas über eine dieser Plattformen erzählt – meine Antwort lautet: ‚Heute ist der schlechteste Zustand, in dem das Produkt jemals sein wird.‘ [...] Wenn irgendein Verbraucher im Moment glaubt, dass eines dieser kostenlosen Produkte zu 100 Prozent korrekt sein wird, dann sollte er sich schämen.“
Diese Aussage legt die Verantwortung für kritisches Denken (kann mir jemand erklären, was das sein soll?) auf den Nutzer ab. Doch was bedeutet es für unsere Informationsgesellschaft, wenn die dominanten Werkzeuge der Zukunft auf einem Prinzip basieren, bei dem sich der Nutzer für seinen Glauben an die Richtigkeit der Antworten „schämen“ sollte? Es bedeutet, dass wir uns in einem glorreichen Zeitalter der selbstbewussten Ahnungslosigkeit befinden, in dem die Grenze zwischen Fakten und Fiktion nicht nur verschwimmt, sondern von den Architekten unserer neuen digitalen Realität (das Thema kommt bald als Essay) als kalkuliertes Feature, nicht als Bug, implementiert wird.
Too Long, Don't Read? Kein Problem: hier das Prompcast 😉

*Die Quelle https://www.cjr.org/tow_center/we-compared-eight-ai-search-engines-theyre-all-bad-at-citing-news.php
Live long and prosper 😉🖖



