
Episode 10.2 - Fishing knowledge in a sea of words without drowning in it 🙂


Die Zettabyte-Ära: Wie exponentielles Datenwachstum unsere Gesellschaft herausfordert
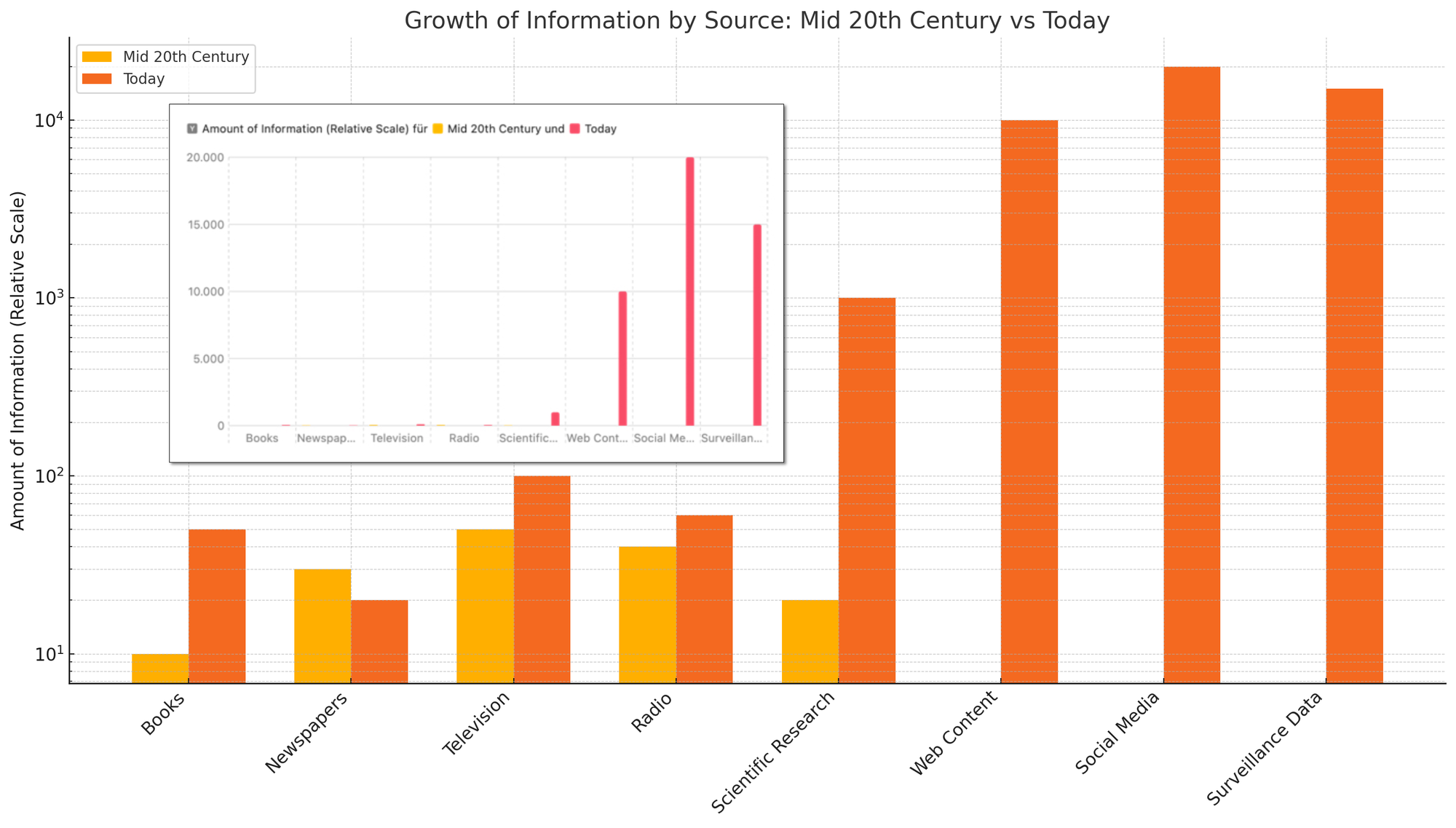
In den letzten fünf Jahrzehnten hat sich das weltweite Datenvolumen in einem nie dagewesenen Tempo vervielfacht. Was noch in den 1970er Jahren mit Megabytes und Gigabytes begann, ist heute zu einer regelrechten Datenexplosion geworden: Das globale Datenaufkommen ist exponentiell gewachsen (man achte auf die Y-Achse der nachfolgenden Grafik 😉 ). Prognosen zufolge wird das weltweit generierte Datenvolumen im Jahr 2028 rund 394 Zettabytes erreichen – eine Zahl, die nur schwer erfassbar ist.
Was bedeutet ein Zettabyte?
Ein Zettabyte entspricht einer Trilliarde Bytes – Es ist eine Zahl mit 21 Nullen (zum Vergleich, 1 Gigabyte hat 9). Diese gigantischen Datenmengen entstehen durch die Digitalisierung aller Lebensbereiche, von sozialen Medien über Industrieanlagen bis hin zu wissenschaftlichen Messdaten*.
Von Daten erdrückt
Mit dieser exponentiellen Zunahme an Datenmengen stehen Unternehmen, Institutionen und auch Privatpersonen vor einer gewaltigen Herausforderung: Immer mehr Menschen und Organisationen fühlen sich von der schieren Masse an Daten regelrecht erdrückt. Über die Hälfte der Unternehmen gibt an, dass das Datenvolumen so schnell ansteigt, dass sie kaum noch Schritt halten können. Die Verwaltung, Speicherung und Analyse dieser Datenberge wird zunehmend komplexer und ressourcenintensiver.
Die Problematik unstrukturierten Daten
Noch gravierender wird das Problem dadurch, dass der größte Teil dieser Daten unstrukturiert ist: Schätzungen zufolge liegen rund 80–90 % aller Geschäftsdaten in unstrukturiertem Format vor. Dazu zählen E-Mails, Bilder, Videos, Sensoraufzeichnungen, Chatprotokolle und vieles mehr. Diese Daten lassen sich nicht einfach in klassische Datenbanken wie mySQL, Oracle oder Postgres einsortieren und sind mit herkömmlichen Methoden nur schwer zu durchsuchen, zu analysieren oder sinnvoll zu nutzen. Fakt ist, dass trotz immensen Investitionen in IT viele Unternehmen Schwierigkeiten haben, diesen Datenberg zu verwalten, geschweige denn, einen Nutzen daraus zu ziehen.
Eine der größten Herausforderungen unserer Zeit
Das exponentielle Datenwachstum und die Dominanz unstrukturierter Daten stellen eine der größten gesellschaftlichen Herausforderungen der Gegenwart dar. Es geht nicht nur um Technik und Speicherplatz, sondern um die Fähigkeit, aus der Datenflut wertvolle bzw richtige Erkenntnisse zu gewinnen, Innovationen voranzutreiben und gleichzeitig Datenschutz, Sicherheit und Nachhaltigkeit zu gewährleisten. Viele Menschen sind von dieser Datenflut überfordert und flüchten sich in Blasen, wo sie versuchen ein Stückchen "Digital Wellbeing" zu finden, egal welche Qualität und Richtigkeit die Information haben, die sie in diesen Blasen auffinden. Man sieht auch schon ganz klar die politischen Auswirkungen dieser Blasen, die den Realitätssinn derer verzerrt, die sich darin aufhalten.
Mit LLMs haben wird endlich eine Technologie, die dieses Problem adressiert.
Large Language Models (LLMs), die die Grundlage aktueller KI-Tools wie ChatGPT oder Gemini bilden, stellen einen entscheidenden Durchbruch im Umgang mit der exponentiell wachsenden Menge unstrukturierter Daten dar. Während klassische IT-Methoden oft an den Grenzen ihrer Leistungsfähigkeit scheitern, bieten LLMs erstmals Werkzeuge, um mit große, unstrukturierte Datenmengen effizient und sinnvoll zu bearbeiten.
LLMs sind darauf spezialisiert, natürliche Sprache zu verstehen, zu analysieren und zu generieren. Sie wurden mit Milliarden von Textbeispielen trainiert und sind dadurch in der Lage, Muster, Zusammenhänge und Bedeutungen selbst in komplexen und heterogenen Textdaten zu erkennen. Das ermöglicht es, unstrukturierte Daten wie E-Mails, Social-Media-Beiträge, Berichte oder wissenschaftliche Artikel automatisiert zu durchsuchen, zu klassifizieren, zu extrahieren und zu interpretieren.
Konkret können LLMs:
- Text- und Mediendaten in strukturierte Informationen umwandeln, indem sie beispielsweise Entitäten, Themen oder Stimmungen erkennen und extrahieren.
- Relevante Informationen aus großen Datenmengen filtern und so die Informationsflut beherrschbar machen.
- Unterschiedliche Medien, Datenquellen und -formate zusammenführen und analysieren, was mit klassischen Methoden oft nicht möglich ist.
- Semantische Zusammenhänge verstehen, sodass sie Kontext und Bedeutung von Texten erfassen können – ein entscheidender Vorteil bei der Analyse unstrukturierter Daten.
Damit eröffnen LLMs erstmals die Möglichkeit, aus der überwältigenden Masse an unstrukturierten Daten wertvolles Wissen zu gewinnen und diese Daten für Entscheidungsprozesse, Innovationen und Automatisierungen nutzbar zu machen. Sie sind somit ein zentrales Werkzeug, um die größte Herausforderung der digitalen Gesellschaft zu bewältigen.
LLMs sind aber selber "Datenbeschleuniger"
Große Sprachmodelle (LLMs) wie ChatGPT oder Bildgeneratoren wie Midjourney tragen paradoxerweise ebenfalls zum Zettabyte-Problem bei. Einerseits helfen sie uns, unstrukturierte Daten besser zu bearbeiten – andererseits beschleunigen sie die Erzeugung neuer Inhalte dramatisch. Innerhalb von Sekunden entstehen durch KI automatisiert Texte, Bilder, Videos oder synthetische Stimmen, die wiederum gespeichert, geteilt und archiviert werden. Damit vervielfacht sich das Datenvolumen nicht nur durch Menschenhand, sondern zunehmend auch durch Maschinen – Wir haben nun eine Datenlawine, die sich selbst beschleunigt - Ein weiterer interessanter Nebeneffekt ist, dass wir bald mehr "machine content" als "human content" haben werden. Was das für LLM's bedeutet, wenn sie mit ihren eigenen Inhalten gefüttert werden ist noch nicht ganz klar.
Allerdings: „Nicht der Bohrer zählt, sondern das Loch“ – Fokus auf den wahren Wert von Daten
Man darf bei dieser Diskussion allerdings niemals Bohrer und Loch durcheinanderbringen, und das ist ein klassisches Beispiel für das Prinzip: „Menschen wollen kein Produkt, sondern das Ergebnis.“ Oder wie es Harvard-Professor Theodore Levitt formulierte: „People don’t want to buy a drill. They want a hole in the wall.“
Auf das Zettabyte-Problem bezogen: Wir sammeln, speichern und erzeugen immer mehr Daten – aber der eigentliche Zweck ist nicht die Datenmenge selbst, sondern bessere Entscheidungen, Erkenntnisse oder Erlebnisse daraus zu gewinnen. Wenn wir den Fokus zu stark auf die bloße Anhäufung von Daten legen (den „Bohrer“), verlieren wir leicht aus dem Blick, worauf es eigentlich ankommt: das „Loch“ – also den Nutzen, den wir aus den Daten ziehen.
In diesem Zusammenhang ist auch die Unterscheidung zwischen Datenquantität und Datenqualität entscheidend. Wer nur möglichst viele Daten sammelt, ohne auf deren Relevanz, Verlässlichkeit oder Kontext zu achten, riskiert, in einem Meer aus Belanglosigkeiten zu ertrinken. Denn: Ein schlechter Datenschatz ist oft schlimmer als gar keiner. Wirklichen Mehrwert schaffen nicht die größten Datenberge, sondern die präzisen, gut aufbereiteten Informationen, die uns helfen, schneller und fundierter zum Ziel zu kommen – zum sprichwörtlichen Loch in der Wand.
Und hiermit kommen wir zum Cliffhanger dieses Newsletters: Was sind "präzise, gut aufbereitete und nutzbare Informationen"? - tja, stay tuned ... ;)
Live long and prosper 😉🖖



